Key Takeaways
- System integrity depends on rigorous change management and observability rather than just rapid deployment.
- Tracking updates requires a centralized source of truth for both code changes and infrastructure state.
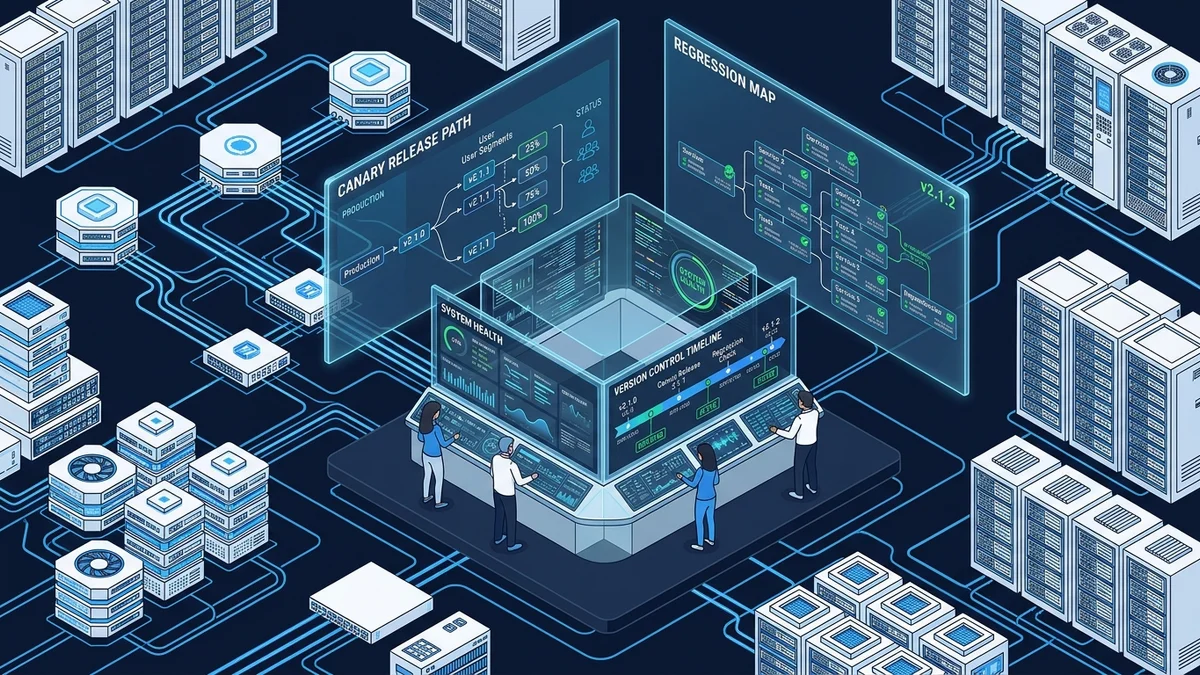
- Implementing automated testing and canary releases minimizes the blast radius of new deployments.
- Technical debt often compounds when updates are pushed without architectural oversight.
- High-availability software relies on a proactive rather than reactive update strategy.
In the fast-paced world of software development, updates are the heartbeat of your application. However, frequent changes can introduce vulnerabilities if not managed with precision. Maintaining system integrity requires a disciplined approach to version control, documentation, and automated validation.
Why do engineering updates threaten system stability?
Every time your team pushes updates to production, you introduce potential points of failure. Even minor refactors can trigger cascading errors if the underlying architectural dependencies are not clearly mapped. Unmanaged changes often lead to regressions that degrade user experience and inflate maintenance costs.
- Regression Risks: New code often conflicts with legacy logic, causing silent data corruption.
- Configuration Drift: Discrepancies between staging and production environments frequently occur during rapid release cycles.
- Dependency Hell: Outdated libraries can conflict with updated packages, leading to unstable runtime behavior.
According to industry data, nearly 70% of production incidents are directly triggered by recent configuration or code changes rather than hardware failures.
If your team struggles with these risks, you might be falling behind on best practices. To learn more about how to structure your foundation, check out our guide on scaling architecture to prevent technical debt.
How can you implement an effective tracking framework?
Visibility is the primary defense against update-related downtime. A robust framework for tracking updates should integrate directly into your CI/CD pipeline, ensuring that every commit is audited. Without a centralized log, your engineering team is essentially flying blind during a release.
- Immutable Audit Trails: Use tools that automatically timestamp every deployment and associate it with a specific pull request.
- Automated Change Reports: Generate automated manifests that compare the current production state against the proposed changes.
- Feature Flags: Decouple deployment from release to allow for controlled rollouts of risky updates.
By abstracting the deployment process, you protect your system from immediate failure. For teams managing complex communication stacks, it is vital to remember the hidden costs of managing multi-channel messaging sessions when pushing updates to live systems.
What are the best tools for monitoring system integrity?
Modern engineering labs rely on observability platforms to gain deep insights into how updates affect performance metrics. You should focus on measuring golden signals: latency, traffic, errors, and saturation. When these metrics spike post-deployment, your tracking system must trigger an automatic rollback.
- Distributed Tracing: Use OpenTelemetry to track requests across microservices.
- Log Aggregation: Centralize logs to identify pattern anomalies in real-time.
- Synthetic Monitoring: Simulate user behavior to ensure updates do not break core conversion paths.
Tools like Prometheus provide the necessary metrics to keep a pulse on your platform. Always ensure that your monitoring stack is as resilient as the application it serves.
How does documentation support long-term maintainability?
Code tells you how the system works, but documentation explains why it was built that way. When tracking updates, engineering teams must maintain architectural decision records (ADRs) to provide context for future contributors. This prevents the degradation of your system design over time.
- ADRs: Record the rationale behind specific technical choices.
- Automated READMEs: Sync your documentation with code headers to ensure it never goes stale.
- Architecture Diagrams: Visualize how system components communicate after major feature updates.
Without proper context, even high-performing teams will eventually struggle to debug complex issues. Keeping your internal wiki updated is just as important as keeping your database indexes optimized. It is this level of diligence that separates high-availability systems from fragile ones.
Why is expert intervention the key to scaling?
Tracking updates is a full-time discipline that requires specialized architectural expertise. Stop stalling your product roadmap with technical bottlenecks and let Renbo Studios accelerate your development with high-availability systems and expert-level integration. We specialize in building robust platforms where update cycles are a routine success rather than a source of stress.
Our dedicated team provides the architectural oversight necessary to maintain your competitive advantage. Visit renbostudios.com today to scale your platform faster with our dedicated engineering lab. Let us transform your deployment process into a reliable engine for growth.



Comments